Adding search capability to a Hugo-based blog
I was working on the documentation for some project, and chose to use Hugo for it. Fits perfectly, but lacks the searching functionality. So I implemented it there, and also decided to add it to my blog too.
It is actually a bit surprising why I didn’t think about it earlier. But then again, using Google’s site-specific search (ololo site:retifrav.github.io) should be good enough for that purpose already, so I just didn’t bother to do something else.
Ways to add search to a static website
Since we are dealing with a static website, and there is no backend with the content database, the options then are as follows:
- Index your content with some external searching engine:
- Google Custom Search is actually not the worst idea, although it won’t work without internet, plus not everyone is too excited about Google;
- Elasticsearch allows you to customize the searching algorithm and you can host it on your own server, but that obviously requires you to run a server for that, and we’re a just static website hosted on GitHub Pages;
- Search in your website contents yourself:
So it’s the second option - to index your website (blog) content and search in it on your own, without relying on external services.
And Hugo official documentation lists several articles on the subject. I started with this manual, but in the end I decided not to use Fuse.js, because simple RegEx match worked out better for me. I also did not create a dedicated search page and put the search field right into the main layout.
Your own RegEx search
Create an index file
The first thing we need is a single file with all the blog articles - stripped from all the HTML, text content only. It also will be easier to have it as a JSON structure.
Let’s then generate such a file. Add JSON output to config.toml:
[outputs]
home = ["HTML", "RSS", "JSON"]Then you need to define a template, which will be used to generate the JSON output: /layouts/_default/index.json:
{{- .Scratch.Add "index" slice -}}
{{- range (where .Site.RegularPages "Section" "blog") -}}
{{ $.Scratch.Add "index" (dict "title" .Title "content" (.Summary | plainify) "permalink" .Permalink) }}
{{- end -}}
{{ $.Scratch.Get "index" | jsonify }}Dashes/hyphens here prevent it from generating lots of redundant empty lines.
As you can see, index.json gets summaries of all the regular pages (posts), their links, titles and creates a JSON file out of it. Why summaries and not the full posts contents? Because of the resulting file size - for example, here are the values for my case (192 posts at the moment):
- posts summaries only: 102 KB
- full posts contents: 1433.6 KB (1.4 MB)
You need to keep in mind that this is what your users will download every time they search something in your blog (it will be cashed after the first time, but nevertheless), so I personally will be using summaries only.
One more thing: sometimes index.json is generated with “doubled” content - every entry is presented there twice for some reasons, so I recommend to check it before deploying. Simply run hugo again and it should fix that.
Add search elements to pages
You can have a dedicated search page or you can add a search field right in the base template. I prefer the latter option.
With my blog layout as an example:
<div class="sidebar-section">
<input id="search-query" placeholder="Search" />
</div>
<div id="search-results" style="display:none;"></div>
<div id="sidebars">
...
</div>The idea is that when user searches for something, the search results block becomes visible and the rest of the sidebar becomes invisible.
Write the search function
Create the /static/js/search.js script:
var sidebars = document.getElementById("sidebars");
var searchResults = document.getElementById("search-results");
var searchInput = document.getElementById("search-query");
// the length of the excerpts
var contextDive = 40;
var timerUserInput = false;
searchInput.addEventListener("keyup", function()
{
// don't start searching every time a key is pressed,
// wait a bit till users stops typing
if (timerUserInput) { clearTimeout(timerUserInput); }
timerUserInput = setTimeout(
function()
{
search(searchInput.value.trim());
},
500
);
});
function search(searchQuery)
{
// clear previous search results
while (searchResults.firstChild)
{
searchResults.removeChild(searchResults.firstChild);
}
// ignore empty and short search queries
if (searchQuery.length === 0 || searchQuery.length < 3)
{
searchResults.style.display = "none";
sidebars.style.display = "block";
return;
}
sidebars.style.display = "none";
searchResults.style.display = "block";
// load your index file
getJSON("/index.json", function (contents)
{
var results = [];
let regex = new RegExp(searchQuery, "i");
// iterate through posts and collect the ones with matches
contents.forEach(function(post)
{
// here you can also search in tags, categories
// or whatever you put into the index.json layout
if (post.title.match(regex) || post.content.match(regex))
{
results.push(post);
}
});
if (results.length > 0)
{
searchResults.appendChild(
htmlToElement("<div><b>Found: ".concat(results.length, "</b></div>"))
);
// populate search results block with excerpts around the matched search query
results.forEach(function (value, key)
{
let firstIndexOf = value.content.toLowerCase().indexOf(searchQuery.toLowerCase());
let lastIndexOf = firstIndexOf + searchQuery.length;
let spaceIndex = firstIndexOf - contextDive;
if (spaceIndex > 0)
{
spaceIndex = value.content.indexOf(" ", spaceIndex) + 1;
if (spaceIndex < firstIndexOf) { firstIndexOf = spaceIndex; }
else { firstIndexOf = firstIndexOf - contextDive / 2; }
}
else
{
firstIndexOf = 0;
}
let lastSpaceIndex = lastIndexOf + contextDive;
if (lastSpaceIndex < value.content.length)
{
lastSpaceIndex = value.content.indexOf(" ", lastSpaceIndex);
if (lastSpaceIndex !== -1) { lastIndexOf = lastSpaceIndex; }
else { lastIndexOf = lastIndexOf + contextDive / 2; }
}
else
{
lastIndexOf = value.content.length - 1;
}
let summary = value.content.substring(firstIndexOf, lastIndexOf);
if (firstIndexOf !== 0) { summary = "...".concat(summary); }
if (lastIndexOf !== value.content.length - 1) { summary = summary.concat("..."); }
let div = "".concat("<div id=\"search-summary-", key, "\">")
.concat("<h4 class=\"post-title\"><a href=\"", value.permalink, "\">", value.title, "</a></h4>")
.concat("<p>", summary, "</p>")
.concat("</div>");
searchResults.appendChild(htmlToElement(div));
// optionaly highlight the search query in excerpts using mark.js
new Mark(document.getElementById("search-summary-" + key))
.mark(searchQuery, { "separateWordSearch": false });
});
}
else
{
searchResults.appendChild(
htmlToElement("<div><b>Nothing found</b></div>")
);
}
});
}
function getJSON(url, fn)
{
let xhr = new XMLHttpRequest();
xhr.open("GET", url);
xhr.onload = function ()
{
if (xhr.status === 200)
{
fn(JSON.parse(xhr.responseText));
}
else
{
console.error(
"Some error processing ".concat(url, ": ", xhr.status)
);
}
};
xhr.onerror = function ()
{
console.error("Connection error: ".concat(xhr.status));
};
xhr.send();
}
// it is faster (more convenient)
// to generate an element from the raw HTML code
function htmlToElement(html)
{
let template = document.createElement("template");
html = html.trim();
template.innerHTML = html;
return template.content.firstChild;
}And add it to the end of <body> of baseof.html (or wherever you describe your layout):
...
<script src="/js/search.js"></script>
</body>
</html>Why in the end of <body>? Because if you add it to the <head>, the script will fail, as there are no elements (#search-query, #search-results, #sidebars) on the page at that point of time.
If you would like to highlight search query in results, then include mark.js library to your baseof.html (somewhere in <head>):
<script src="/js/mark.js"></script>If you don’t want highlights, then comment out the line with new Mark(....
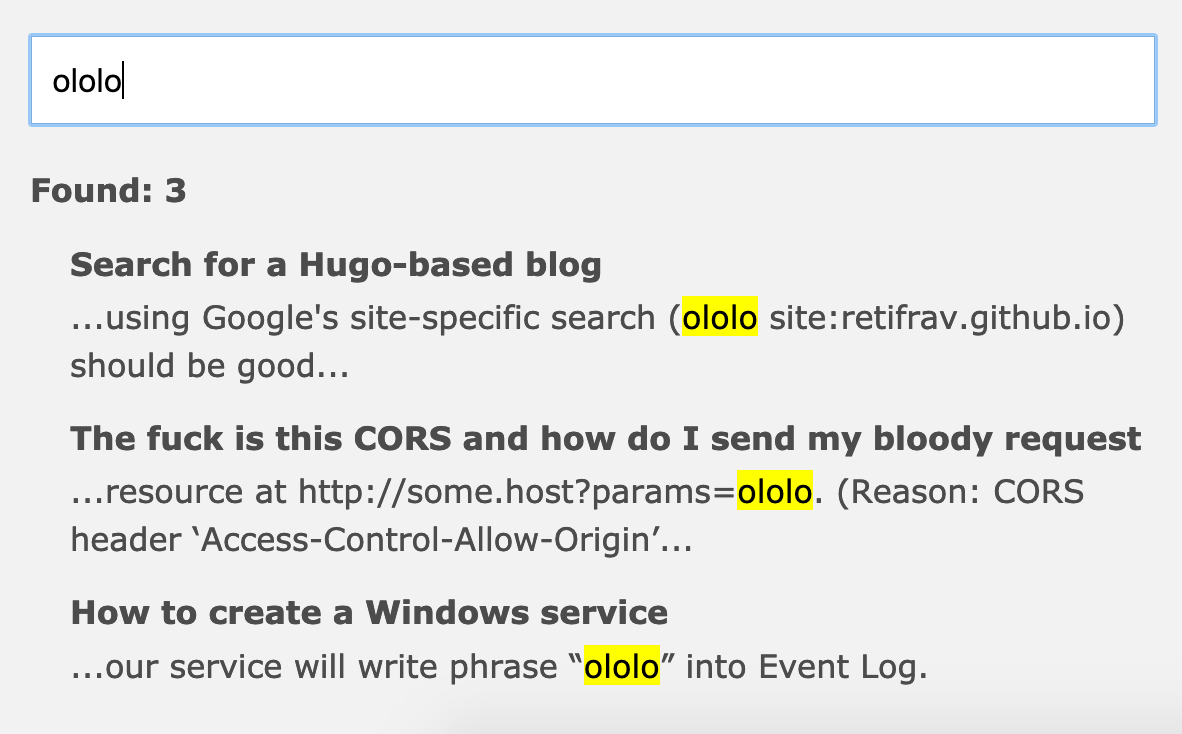
So, here’s how it looks in action:
If video doesn’t play in your browser, you can download it here.
As a bonus, since the script is using RegExp, you can try passing actual regular expressions as search queries, not just “plain” words and phrases. Although, taking excerpts and highlighting matches might require further configuration in that case.

